
🔥Claude Opus 4.6 vs. Sonnet 4.6 Coding Comparison ✅
SAShrijal Acharya·March 5, 2026 (4 months ago)
16 reactions2 comments
ai
programming
python
productivity
Anthropic recently dropped the updated Claude 4.6 lineup, and as usual, the two names everyone cares about are Opus 4.6 and Sonnet 4.6.
Opus is the expensive “best possible” model, and Sonnet is the cheaper, more general one that a lot of people actually use day to day. So I wanted to see what the real gap looks like when you ask both to build something serious, not a toy demo.
Benchmark-wise, there’s a difference of course, but it doesn’t look that huge when it comes to SWE and agentic coding.
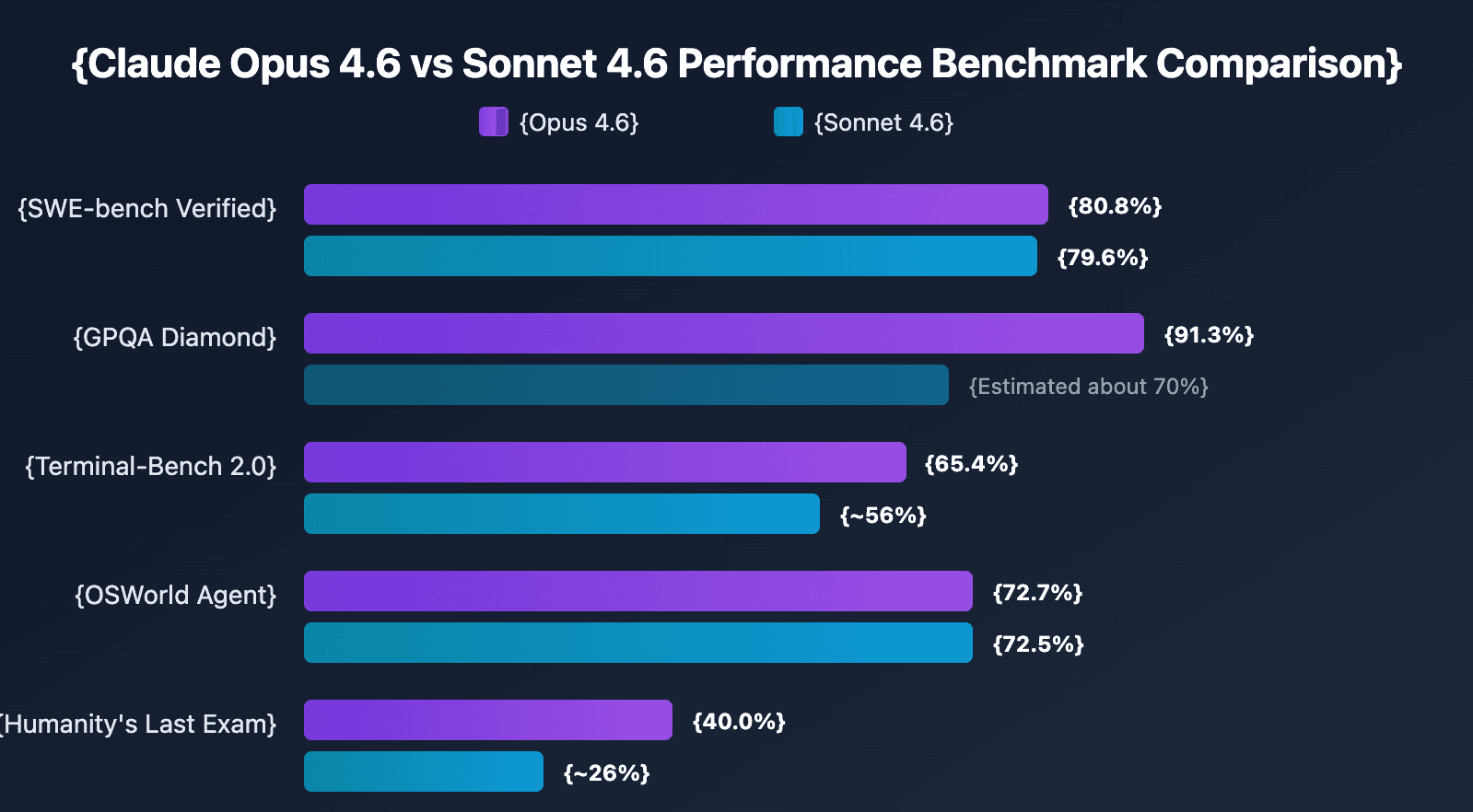
I kept it super basic: one test (but a big one), same prompt, same workflow. I just compared how close they got without me stepping in.
⚠️ NOTE: Don’t take the result of this test as a hard rule. This is just one real-world coding task, run in my setup, to give you a feel for how these two models performed for me.
TL;DR
If you just want the takeaway, here’s the deal with these models:
First, Opus 4.6 is the peak for coding right now. At the time of writing, it’s basically the OG, and nothing else comes that close.
- Claude Opus 4.6 had a cleaner run. It hit a test failure too, but fixed it fast, shipped a working CLI + Tensorlake integration, and did it with way fewer tokens. Rough API-equivalent cost (output only) came out around ~$1.00, which is kind of wild for how big the project is.
- Claude Sonnet 4.6 Surprisingly close for a cheaper, more general model. It built most of the project and the CLI was mostly fine, but it ran into the same issue as Opus and couldn’t fully recover. Even after an attempted fix, Tensorlake integration still didn’t work. Output-only cost was about ~$0.87, but it used way more time and tokens overall to get there.
💡 Obviously, this isn’t a test to “compare” the two head-to-head. It’s just to see the difference in code quality. In general, there’s never really been a fair comparison between Opus and Sonnet since their very first launch, Opus has always been on another level.
Test Workflow
ℹ️ NOTE: Before we start this test, I just want to clarify one thing. I'm not doing this test to compare whether Sonnet 4.6 is better than Opus 4.6 for coding, because obviously Opus 4.6 is a lot better. This is to give you an idea of how well Opus 4.6 performs compared to Sonnet.
For the test, we will use everyone's favorite CLI coding agent, Claude Code.
As both models are from Anthropic, it works best for both and is not biased toward either.
We will test both models on one decently complex task:
- Task: Build a complete Tensorlake project in Python called
research_pack, a “Deep Research Pack” generator that turns a topic into:
- a citation-backed Markdown report, and
- a machine-readable source library JSON with extracted text, metadata, summaries, you get the idea.
It also has to ship a nice CLI called research-pack with commands like:
research-pack run "<topic>"research-pack status <run_id>research-pack open <run_id>
We’ll compare the overall feel, code quality, token usage, cost, and time to complete the build.
💡 NOTE: Just like my previous tests, I’ll share each model’s changes as a
.patchfile so you can reproduce the exact result locally withgit apply <file.patch>.
Why Tensorlake?
Tensorlake is a solid choice for this Opus 4.6 vs Sonnet 4.6 test because it is a real platform with enough complexity to quickly show whether a model can actually build something end to end. It has an agent runtime with durable execution, sandboxed code execution, and built in observability, so the test is not just writing a few functions, it is wiring up a production workflow.
And selfishly, it is also a good dogfood moment. 👀 If a model can spin up a Tensorlake project from scratch and get it working, that is a pretty strong sign for two things: these recent models are getting scary good and how usable Tensorlake is for building serious agent style pipelines.
Coding Tests
Test: Deep Research Agent
For this test, both models had to build the research_pack Tensorlake project in Python. The goal was simple: give it a topic, it crawls stuff, figures out sources, improves them, and spits out:
report.mdwith[S1]style citationslibrary.jsonwith the full source library- a clean CLI:
research-pack run/status/open - plus Tensorlake deploy support so you can trigger it as an app, not just locally
You can find the prompt I’ve used here: Research Agent Prompt
One thing that went a bit crazy is that both models ran into basically the exact same/similar issue during the run.
That shows how similarly these models can behave, which is kind of creepy. If you give them the exact same task and constraints, they’ll often make similar choices. I wanted to call that out because you might’ve noticed the same pattern too.
Not surprisingly, Opus fixed it much faster and with way fewer tokens. Sonnet took longer, burned a lot more context trying to debug it, and even after the fix pass, it still didn’t fully work.
Claude Opus 4.6
Opus was pretty straightforward.
It did hit a failure while running tests, but it was a quick fix. After that, everything looked clean: CLI worked, offline mode worked, and overall all the feature flags seem to work perfectly.
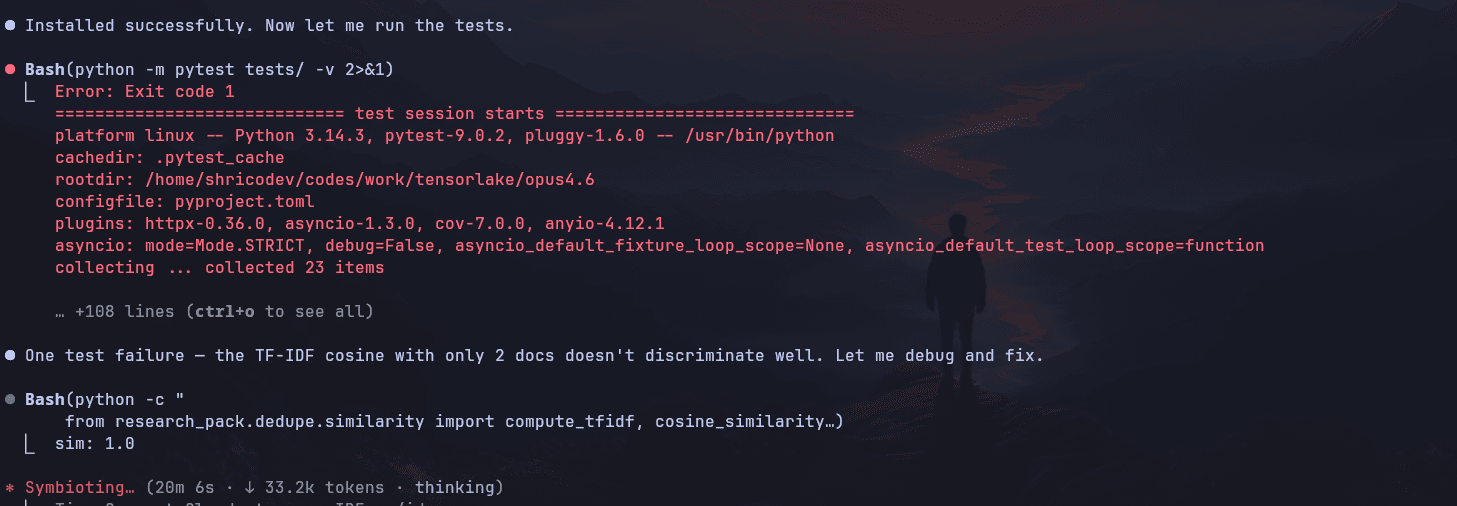
Here’s the acceptance checklist it generated at the end, I really love it as it created this after making sure all tests pass, and everything is in place, that's how it's done.

Here's the demo of the working CLI:
Note: The API key visible in the below demo videos has been revoked. Please don’t try to use it.
...and how it integrates with Tensorlake:
You can find the code it generated here in a patch file: Opus 4.6 Patch file
- Cost: ~$1.001
ℹ️ NOTE: As I'm using a Claude plan and not on API usage, this is roughly calculated based on the input/output tokens.
- Duration: 20 minutes 6 seconds + ~1 min 40 sec for the fix
- Output Token Usage: 33.2K + ~4K for the fix
- Code Changes: 156 files changed, 95013 insertions(+)
ℹ️ You can see the complexity of the project for yourself, and you’ll probably be shocked at how good these models have gotten. It’s no longer just boilerplate or small refactors. They can build a complete, end-to-end project from scratch from a single prompt. We’re officially in the real AI era.
Claude Sonnet 4.6
Sonnet was… close, but not quite as clean as Opus.
Just like Opus, it ran into a test failure during the run. This is one of those things you’ll notice with similar models: same prompt, same codebase, and they sometimes hit the exact similar weird issue.
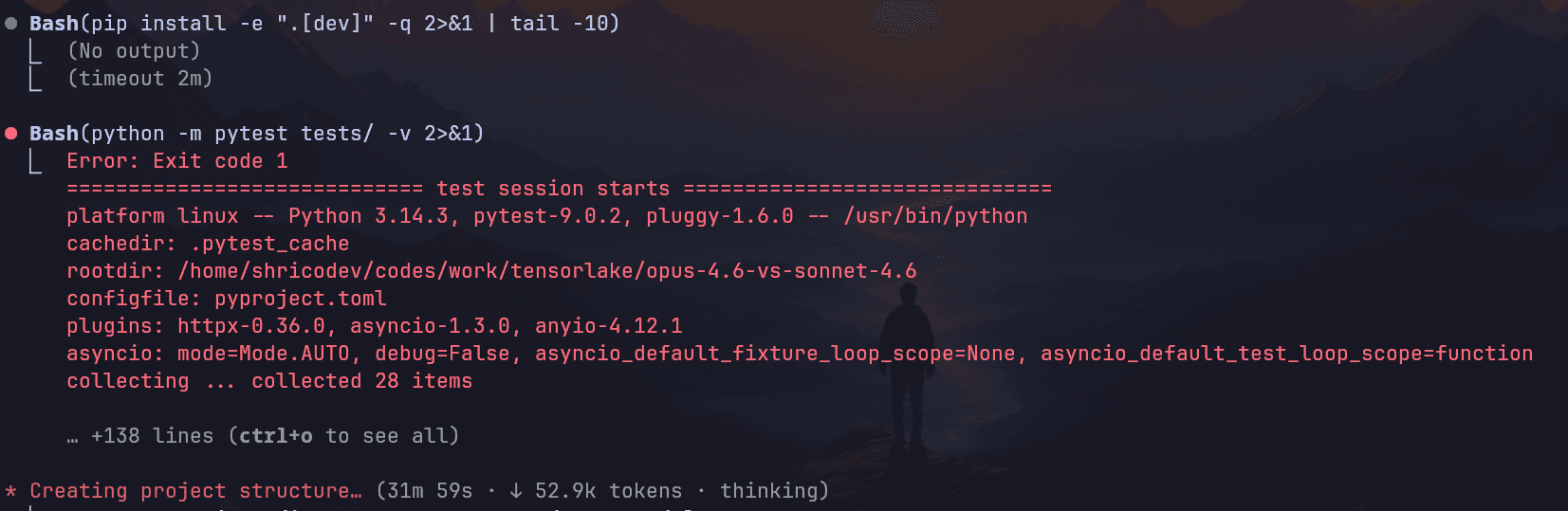
Here’s the demo of the CLI (you’ll see it mostly working, but there are some rough edges) and not as well implemented as Opus:
...and how it integrates with Tensorlake:
It's not working as you can see. Sonnet did attempt a fix, but still couldn't get to a working state with Tensorlake. But overall, it was super close.
You can find the code it generated here: Sonnet 4.6 Patch
- Cost: ~$0.87
ℹ️ Same as Opus 4.6, this is an approximate cost based on the input/output tokens.
- Duration: 33 minutes 48 seconds + ~3m 18s for the attempted fix
- Output Token Usage: 52.9K + ~5K for the fix (didn't work)
- Code Changes: 88 files changed, 23253 insertions(+)
🤷♂️ I can’t really complain about Sonnet’s performance, other than this one issue. It still got almost everything working. And to be fair, Sonnet isn’t Anthropic’s flagship coding model like Opus. It’s more of a general-purpose model, and Opus also comes with a pretty big cost difference, so the gap in code quality is kind of expected.
And please don’t try using the API keys shown in the video, as it’s already revoked.
Conclusion
Opus as a lineup is just too good. If you want an end-to-end product that works most of the time with minimal hand-holding, go with Opus. If you want something cheaper, and you’re okay finishing the last bit yourself, Sonnet is still solid.
Even in this one test, you can already see the gap in implementation quality, token usage, and time spent.
And if Anthropic can cut Opus to half its price, or even get it close to Sonnet’s, it’d be over for most other models.

For me, the best way to use these models is still the same: let them build most of it fast, then run it, test it, and clean up the rough parts yourself.
Let me know your thoughts in the comments. ✌️